
DeepliteRT
Accelerate AI on Arm CPUs using
ultra-compact quantization

Join the Community
Try our deep learning model
optimization platform for free!



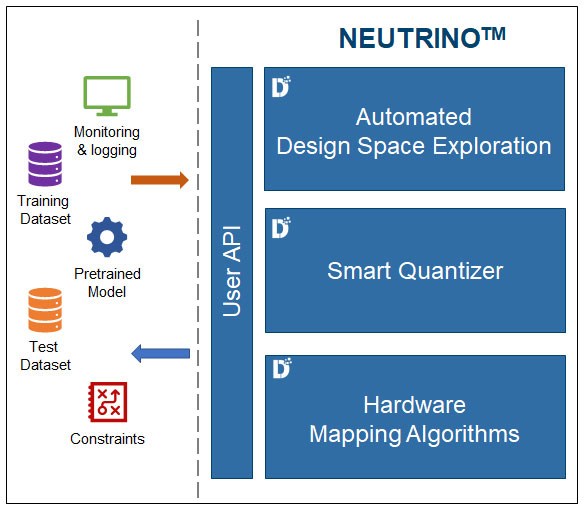
Introducing Neutrino™
Deeplite Neutrino™ leverages a novel multi-objective design space exploration approach to automatically optimize high-performance DNN models, making them dramatically faster, smaller and power-efficient without sacrificing performance for real-time and resource-limited AI environments.
DeepliteRT
Accelerate computer vision ML inference with high-performance, 2-bit quantization runtime for Arm Cortex-A CPUs.
· Deploy advanced video analytics and computer vision features on cost-effective Arm CPUs.
· Faster time-to-market and compatibility for existing mobile devices, surveillance cameras, and machine vision systems.
· Lower-cost hardware solutions than developing custom GPU or NPU hardware designs.


Automotive
Real-time deep learning on low-power processors to help move people and things around the planet safely.
Learn More
Smartphones
On-device AI for an engaging experience that captivates the user and conserves battery life.
Learn More
Smart Cameras
Understand, analyze and make predictions from video and images in an instant using real-time deep learning.
Learn More
IoT Devices
Deploy deep learning on edge devices and smart sensors to generate new insights and intelligence.
Learn More





